最近给小程序的后端日志加上了实时输出到前端功能,为了展示就得保存日志,又考虑到日志是时序数据,自然就选择了时序数据库 InfluxDB,并且通过 Docker 部署。刚上线的一两天没有什么问题,各方面运行都很平稳,没过几天的一个早上突然收到了阿里云的报警,说内存占用超过了 95%。
这便是噩梦的开始。
罪魁祸首
收到报警后看了一下系统各项指标,不仅内存占用高,CPU、磁盘使用率都是满负荷。
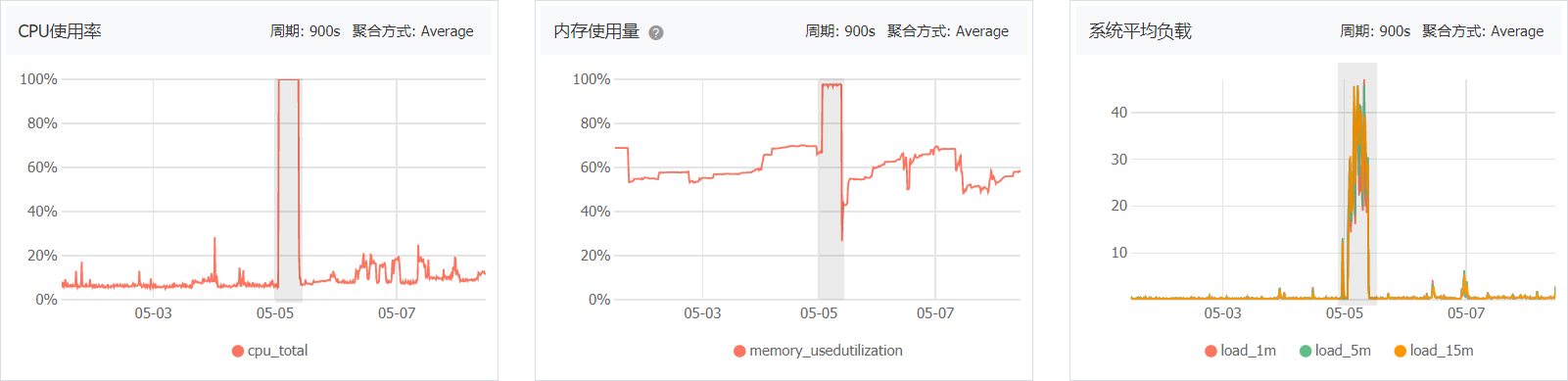
在凌晨一点半左右内存暴涨,紧接着 CPU 使用率也达到 100%。这个场景似曾相识,因为之前使用过 InfluxDB,也遇到过内存暴涨,结合前几天又用上了 InfluxDB,基本可以断定是 InfluxDB 的锅。
重启服务器后一切都恢复正常,但是 InfluxDB 可能随时又出现状况,只能一直盯着各种指标,盯数据的时候发现 InfluxDB 的内存占用肉眼可见地增长,可以说很恐怖了。
尝试解决
好在 InfluxDB 是通过 Docker 部署的,可以很方便地限制内存使用,尝试通过 docker-compose.yml 配置:
将 InfluxDB 可以使用的内存限制在 500MiB,超过这个数值就会被 kill,然后又自动重启。虽然这样可以避免 InfluxDB 将系统拖垮,但频繁 OOM 又重启终究不是什么好办法。
更改索引方式
查了一些资料后得知 InfluxDB 默认的索引是在内存上维护的,不断地数据增长会使用越来越多的内存,并有一个参数 index-version 可以设置索引方式1。如果是直接在主机上部署的可以修改配置文件,Docker 部署则需要通过环境变量设置:
将索引数据存储在磁盘上,可以通过日志或者查看分片的目录结构验证修改是否生效,若索引方式为 tsi1,在分片目录下会有一个名为 index 的目录,inmem 索引则没有。
具体位置是 /var/lib/influxdb/data/<数据库>/<保留策略>/<分片>。
[root@izuf6czs1dw6siz3zokdiez 1_day]# ls
1 10 11 12 13 14 15 16 18 19 20 21 3 4 5 6 7 8 9
[root@izuf6czs1dw6siz3zokdiez 1_day]# cd 15
[root@izuf6czs1dw6siz3zokdiez 15]# ls
000000001-000000001.tsm fields.idx index禁用状态监控
默认情况下 InfluxDB 会维护一个 _internal 库,来监控系统状态,但是会产生不必要的数据,官方不推荐在生产环境下使用 _internal 库2。
InfluxData does not recommend using the
_internaldatabase in a production cluster. It creates unnecessary overhead, particularly for busy clusters, that can overload an already loaded cluster. Metrics stored in the_internaldatabase primarily measure workload performance and should only be tested in non-production environments.
添加环境变量:
效果验证
更改索引方式后内存使用依然在缓慢增长,但是保留策略设置的是一天,需要等到更改生效一天后才能看出真实的效果(待更新)。
超过保留策略(24 小时)的时间后(27 小时)内存增长停止,目前稳定在 235.3MiB,大致符合预期。
https://www.jianshu.com/p/dbbb73b537e1 "InfluxDB频繁OOM问题排查 - 简书"↩︎
https://docs.influxdata.com/platform/monitoring/influxdata-platform/tools/measurements-internal/ "InfluxDB _internal measurements and fields"↩︎